Cloud Computing et Architectures "Scalables"
ou comment utiliser la flexibilité du Cloud pour monter en charge
INSSET - Master 2 Cloud Computing
Novembre 2016 - Bertrand Tornil
Montée en charge?

Rappelons en quoi consiste un Service Web (over HTTP)
Un client fait une requête HTTP
GET /bob http/1.1
Host: www.mon_super_service_web.com
Le serveur
- ... reçoit la réquête...
- ... la traite ...
- ... et génère une réponse
HTTP/1.1 200 OK Content-Type: text/html Content-Length: 9 Hello bob
La charge monte

Raisons ?
Plusieurs clients en même temps
Des résultats plus lourds depuis la DB
L' API d'un partenaire qui "lag"
...
Solution 1
Investir dans une machine plus puissante

Forcément limité.
Et le prix s'envole.
Solution 2
Répartir la charge sur plus de machines
On achète de nouvelles machines (commande, installation, monitoring, test, déploiement)
OU
On lance une nouvelle instance sur le Cloud
Souplesse \o/
Notion de capacité élastique
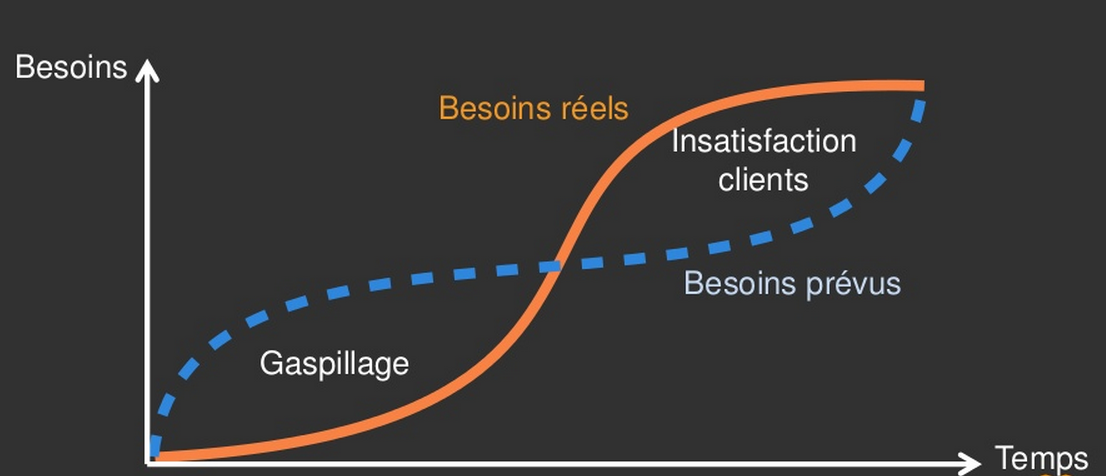
Notion de capacité élastique
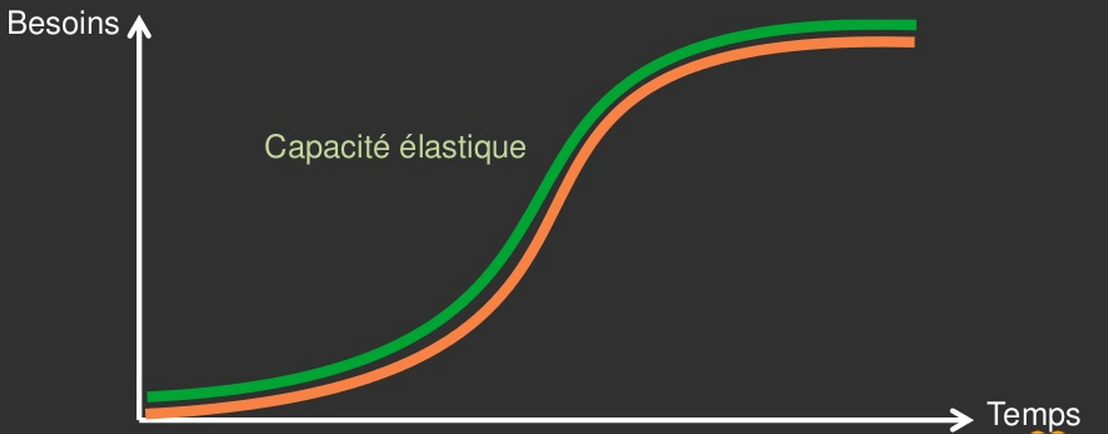
Premiers temps
Séparation des principales briques de l'architecture
- Le serveur web
- La DB
C'est la première marche.
Stratégie multi-frontal
On "clone" le serveur web
- Sur AWS ou autre IAAS : en 1 commande, nous avons 1 nouvelle instance bootée en 1 minute
- Un outil de gestin de configuration comme puppet, chef ou salt-stack : industrialisation du déploiement de la configuration
- Et un outil comme capistrano ou fabric : industrialisation du déploiement du code
Et pour répartir les requêtes entre les frontaux, on place un "load balancer" devant
Une image valant souvent mieux qu'un long discours...
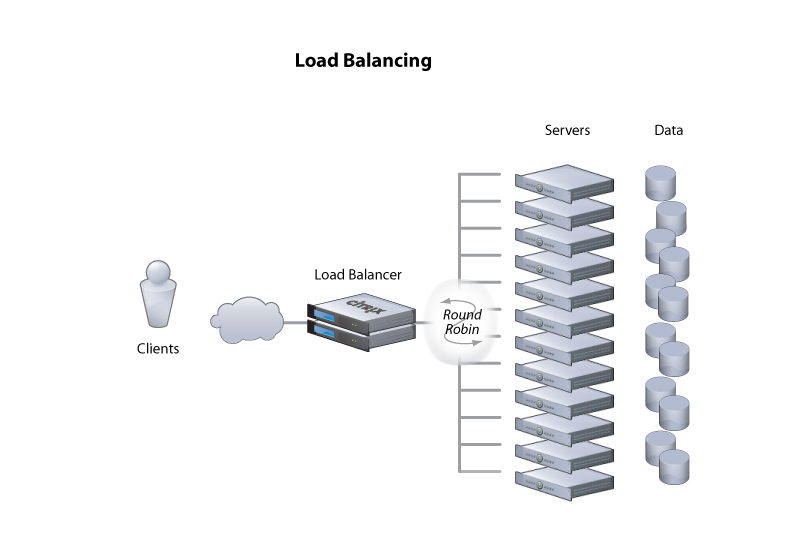
Stratégies de "Load balancing"
Round robin
Signifie tourniquet.
Avec un tel ordonnancement, chaque machine est servie l'une après l'autre, sans notion de priorité
Least connected
Le load-balancer doit pouvoir connaître l'état des connexions des frontaux
Il adapte le flot selon la charge réseau du frontal
less loaded
Cette fois c'est l'état de charge général du frontal qui est pris en compte
Remarques sur le multi-frontal
Cette stratégie permet de monter pratiquement indéfiniment. C'est une recette magique, qui a fait ses preuves
Chez Facebook, on estime qu'ils ont monté plus de 180000 serveurs (donnée 2013, serveurs web, et autres)
Néanmoins, elle soulève de nouveaux problèmes :
- Le partage d'information entre frontaux (session utilisateurs)
- Les déploiements
- La maintenance
Les données
Arrive un moment, ou l'ajout de serveurs webs ne peut plus seul, régler le problème de la montée en charge : tous ces seveurs webs "attaquent" la même base de données....
... qui elle aussi arrive à sa limite
L'accès aux données est notre nouveau point de contention.
Et bien nous allons augmenter le nombre de machines pour la DB
Ok, mais comment ?
On ne peut pas simplement cloner. Les DB seraient rapidement désynchronisées les unes des autres.
La réplication
Pour les services qui se caractérise côté DB par beaucoup de lectures, par rapport aux ecritures
Une machine est "Master" : c'est sur elle qu'on effectue toutes les commande en écriture
Une ou plusieurs machines sont des "Slaves" ; sur lesquelles les opérations de lecture sont effectuées
Attention : gestion du retard
Mais au bout d'un moment...
Chaque machine qui héberge une DB peut arriver à sa limite.
Dans le schéma master-slaves, le master devient à son tour la faiblesse de l'architecture.
Surtout sur les services où le nombre d'écritures est du même ordre de grandeur que le nombre de lecture (Réseau sociaux, fils de commentaires, discussions)
Solution #1 : Partitionnemnent vertical
On dispatch les tables sur plusieurs machines
On commence à dénormaliser le modèle : certaines tables ne pourront plus être jointes.
Solution #2 : Partitionnement horizontal
le Sharding
Principe : on coupe les tables en plus petites tables que l'on peut mettre sur des bases de données différentes.
Avantage: assez simple
Inconvénient: difficile à faire évoluer en production
Une réponse peut être de pré-sharder ses tables dès le début.
Le NoSQL
Avec la dénormalisation du modèle, on se retrouve à s'intéresser à d'autre technologies.
On y arrive... (teasing ...)
Le NoSQL
un peu de théorie
Le théorème CAP de Brewer (1998 - 2000)
en très approximatif
C : Consistency
Un service distribué est dit "consistent" s'il opère ses opérations entièrement... ou pas du tout ... et partout !
Notions de transactions, propriétés ACID (Atomicité, Cohérence, Isolation, Durabilité)
Tous les nœuds du système voient exactement les mêmes données au même moment
Dans la pratique, c'est une propriété très difficile à atteindre, même pour un système non distribué Linearisability, sequential consistency, or serializability, or snapshot isolation, sequential, serializable, repeatable read, snapshot isolation, or cursor stability ,causal consistency, PRAM, and read-your-writes consistency.
A : Availability
Un service distribué est "available"... s'il marche...
On considère qu'il marche quand chaque client peut utiliser le service en écriture et en lecture
Garantie que toutes les requêtes reçoivent une réponse
P : Partition Tolerance
Dès lors que les données sont distribuées en plusieurs endroits (machines, lieux), aucune panne moins forte qu'une destruction globale du réseau ne peut justifier un arrêt du service
Que dit le théorème CAP ?
Dans un système distribué, des 3 propriétés CAP... on peut n'en garantir que 2
Et bien, nous voilà bien ...
Quelles conséquences ?
Dans un système distribué, on a forcément des partitions qui se forment. Désolé, le réseau n'est pas fiable, et même dans une même machine, ca n'est pas assuré... On garde donc systématiquement P et on doit donc faire le choix difficile entre C et A.
Dans un certain sens, le mouvement NoSQL consiste à faire des choix qui se concentrent sur la disponibilité en premier lieu, et la cohérence en second; les bases de données qui adhèrent aux propriétés ACID (Atomicité, Cohérence, Isolation, Durabilité) font l'inverse.
Exemple : garder le AP
concept du "Eventually Consistent" (W.Vogels)
notions de replicas(N), de quorum en lecture(R), en écriture(W)
les "vector clocks" retracent l'historique des opérations, et permettent à l'applicatif de trancher. Parfois selon une logique métier
L'art de la distribution des données
Nous avons des données, et plusieurs machines sur lesquelles les envoyer
Comment allons-nous nous y prendre ?
Table de hachage persistante
les informations sont ici stockées sur un nœud unique.
Ce mode de stockage est donc efficace tant que le volume de données stockées et la charge de requêtes n’excèdent pas les capacités de la machine.
En outre aucune tolérance aux pannes n’est ici admise puisque les données ne sont pas redondées.
Sharding en distribution modulo
On distribue les clés selon le modulo (du md5 de la clé par exemple)
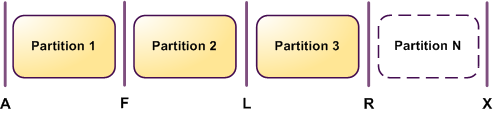
- C'est très simple simple
- mais on doit re-distribuer N-1/N data lors de l'ajout d'un N+1-ième noeud
Sharding en hashing consistent
Un hashring est généré
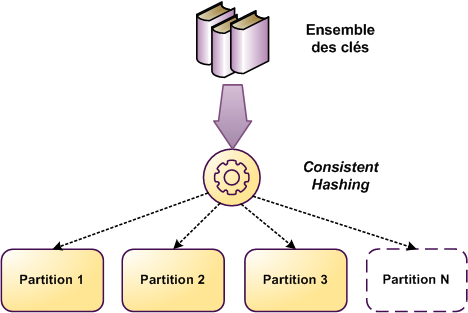
- C'est plus complexe
- par contre, on ne doit re-distribuer que 1/N data lors de l'ajout d'un N+1-ième noeud
Réplication sur N instances
Type simple : 1 partition par instance
Type replica : M partitions par instances
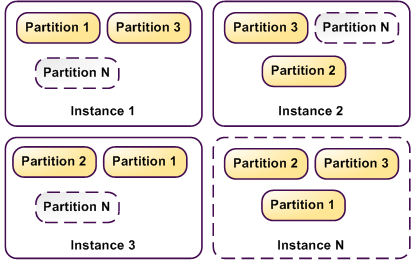
- On retrouve la notion de relachage de la consistence
- Dynamo (Amazon) et BigTable de google fonctionnent de cette manière
Le NoSQL
Généralités
- Le NoSQL regroupe de nombreuses bases de données,
- assez récentes pour la plupart,
- avec une logique de représentation de données non relationnelle
- et qui n’offrent donc pas une interface de requêtes en SQL.
À propos du NoSQL
Ce n'est pas une solution miracle pour le stockage de données
Par contre, la logique de représentation des données différentes peut apporter une reponse satisfaisante à certains problèmes
Et comme toujours
Use The Right Tool !

Les NoSQL "Clé-Valeur"
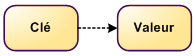
- En général, très rapides
- Possible de requêter sur la clé, peu sur les valeurs
- Exemples : Memcache, Riak, Redis, Voldemort
Les NoSQL "Clé-Colonne"
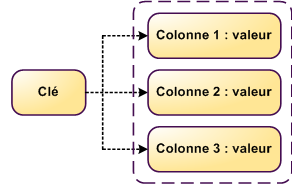
- Colonnes différentes pour chaque ligne
- Capacité à stocker des listes d'informations
- Requétage, indexes
- Capacité d'accéder à des intervalles de colonnes
- Exemples : HBase, Cassandra
Les NoSQL "Clé-Document"
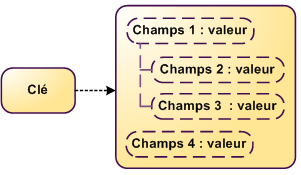
- Extension du modèle clé-valeur
- Un document contient des données organisées de manière hiérarchiques (XMl, JSON)
- Indexes, notions de champs, requêtes
- Exemples : MongoDB, CouchDB
Les NoSQL "Graphs"
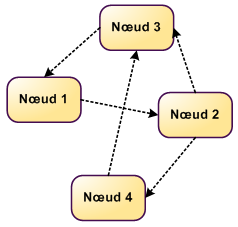
- stocke des données liées par des relations
- réseaux sociaux
- base de données géographiques
- Exemples : Neo4j, HypergraphDB, FlockDB
Ajouter un système de cache devant les données
Nous allons utiliser un stockage plus rapide qu'une base de donnée, mais non-relationnel
Dans les fait, cela revient à mettre en oeuvre des techno comme memcache. Il s'agit d'un cache en mémoire, accessible au travers du réseau. Il a été développé par Livejournal.
Par exemple, nous remplaçons:
function get_by_id(id):
return query('SELECT FROM ma_table WHERE id=%d' % id).fetch_one()
function get_by_id(id):
if cache['ma_table'].get(id) is not null:
// la valeur est en cache : pas besoin de requêter la DB
return cache['ma_table'].get(id)
else:
// la valeur n'est pas en cache, on requête
res = query('SELECT FROM ma_table WHERE id=%d' % id).fetch_one()
// et on garde la réponse pour plus tard
cache['ma_table'].set(id, res)
return res
Mais attention... de nouveaux problèmes se présentent :)
There are only two hard things in Computer Science: cache invalidation and naming things. -- Phil Karlton
Pour aller plus loin :
- cache de listes
- cache d'élément de listes
- structure complexes, imbriquées
- ...
Avec toutes ces machines / instances
Fallacies of Distributed Computing
- The network is reliable.
- Latency is zero.
- Bandwidth is infinite.
- The network is secure.
- Topology doesn't change.
- There is one administrator.
- Transport cost is zero.
- The network is homogeneous.
Some Case Studies
Case study #1
IsCool Entertainment
La montée en charge du jeu IsCool
Les prémisses
Premiers développements Facebook
Application virale d’échange de points entre amis : IsCool
LAMP / FBML sur Ubuntu
Octobre 2008 : Ouverture de l’application au public
Novembre 2008 : Les premiers problèmes
16 novembre 2008 : "Patron, passe-moi la carte de la boite, on passe sur AWS"
2009
En 7 mois, de 0 à 846.000 visiteurs uniques par jour
Sharding massif (certaines sur 500 tables, éparpillées sur 20 serveurs mysql)
Memcached
Multiplication des frontaux
fin 2009
Si IsCool avait été un site web
- 2ème site de jeu en france
- 25ème site français (pages-vues / mois)
2010 refactor -> v2 -> v3
Sans interruption de service à partir de février 2010
Passage à git
Transistion progressive à symfony 2
Redis (depuis la version 1.0)
Utilisation d'un outils de monitoring exotique : Pinba
Refonte des briques les plus chargées (échange de points, leaderboard)
DevOps, DevOps, DevOps
En 2011, à son plus haut : quelques chiffres
20M pages vues / jour (35M en pic)
130 000 sessions php simultanées sur l'ensembre des frontaux (en soirée sur certaines opérations)
Record à 1.4Ma de points échangés / jour
Au total, 14M de personnes seront passées sur le jeu
Aujourd'hui
Le jeu est en MVC javascript + appels serveur en JSON-RPC 2.0
Encore 6M appels / jours
Toujours 200000 joueurs par jour
Utilisation de RabbitMQ
Case study #2
AirBnB Talk - Berlin - 2012
30+ Millions Utilisateurs en moins de 2 ans
25000 créations de comptes le 1er jour !
Au feu !!!
scaling = replacing all components of a car while driving it at 100mph
C'est bête, mais
404 sur le favicon...
Ne pas oublier le favicon !!
La Stack
Nginx
Django
Postgresql
Redis
La stack... 2ème étage
Nginx
HAProxy
Django
Postgresql
Redis
Memcached
Gearman
DB Instagram
La plus grosse instance sur EC2 : 68GB de RAM
-> vertical partitionning
- user_db
- photos_db
- ....
Next stage
photos_db > 60GB
-> horizontal partitionning (sharding)
Technique made in Instagram : pre-sharding
Utilisation des schemas postgresql
Par exemple
machineA:
shard0
photos_by_user
shard1
photos_by_user
shard2
photos_by_user
shard3
photos_by_user
Par exemple (2)
machineA: machineA’:
shard0 shard0
photos_by_user photos_by_user
shard1 shard1
photos_by_user photos_by_user
shard2 shard2
photos_by_user photos_by_user
shard3 shard3
photos_by_user photos_by_user
Par exemple (3)
machineA: machineA’:
shard0
photos_by_user
shard1
photos_by_user
shard2
photos_by_user
shard3
photos_by_user
Case study #3
Mysql Conference - 2012
Premier étage (Mars 2010)
- rackspace
- 1 web
- 1 DB
Deuxième étage (Janvier 2011)
- AWS EC2 + S3 + Cloudfront
- 1 nginx + 4 web engines
- 1 mysql master + 1 slave
- 1 task queue + 2 task processor
- 1 mongodb
Troisième étage (Octobre 2011) : 11 MAU
- AWS EC2 + S3 + Cloudfront
- 2 nginx + 16 web engines + 2 API engines
- 5 mysql master + 9 slave
- 4 noeuds cassandra
- 15 membase
- 8 memcache
- 10 Redis
- 3 task queue + 4 task processor
- 4 noeuds elastic search
- 3 mongodb
C'est sûr que ca va planter...
Keep it simple (Avril 2012) : 20 MAU
- AWS EC2 + S3 + ELB - Akamai
- 90 web engines + 50 API engines
- 66 mysql master + 1 slave chacun
- 51 memcache
- 56 Redis
- 1 Redis task queue + 25 task processor
- Solr
Pourquoi AWS ?
Disponibilité, support
Services intéressants
Instances prêtes en 1 minute
"Great tools"
Mysql
Memcache
Redis
Out of the box, they won't scale past 1 server, won't have high availability, won't bring you a drink.
Retour sur les stratégies de stockages
Clustering VS Sharding
| Clustering | Sharding |
|---|---|
| Distribue les données sur les noeuds automatiquement | Distribue les données sur les noeuds manuellement |
| Les données peuvent bouger | Les données ne peuvent pas bouger |
| Rebalance les données entre les noeuds pour distribuer la charge | Découpe les tables de données pour distribuer la charge |
| Les noeuds communiquent entre eux | Les noeuds s'ignorent |
Le clustering est séduisant
Cassandra, Membase, HBase, Riak
MAIS
- Technologies jeunes
- Compétences difficiles à trouver
- Et la magie du clustering en fait sa force et sa faiblesse
Finalement : sharding avec stratégie de preshard (databases dans mysql)
Case study #4
http://highscalability.com - 2013
Stats
Le traffic double toutes les 15 mois.
67,328,706 visiteurs uniques
4,692,494,641 pages vues
240 serveurs (2012)
Historique dans EC2
2005 création
2006 les logos sur S3
2007 les miniatures sur S3
2008 EC2 pour les traitement asynchrones
2009 EC2 pour les frontaux web : 1 journée de downtime pour basculer sur EC2
Retour d'expérience AWS
Racker des serveurs n'est pas marrant et chronophage, surtout pour une petite équipe
La croissance n'est pas prévisible, surtout sur les débuts
EC2 n'est pas "a silver bullet" : latence réseau, IO déplorables. Prévoir de fonctionner avec. Le bénéfice ? on peut grandir autant que l'on veut
Tenir compte des limites d'EC2
qui ne sont pas connues à priori, et qui évoluent dans le temps
Concept de attraction des données (data gravity)
Les données étant les choses les plus pénibles à bouger, tout ce qui a besoin d'y accéder ne doit pas être loin
Une fois les données dans le cloud, autant tout basculer dessus
The end ?
Nous n'avons parlé que de la monté en charge côté technique
Quand l'équipe autour d'un projet grandit,
elle «scale up» en même temps que son projet
Certains problèmes peuvent se produirent
Ralentissement paradoxal du développement
Déploiement de plus en plus compliqué
Tout changement devient risqué
Quelques solutions
Méthodes agiles
Devops
Microservices
...
THE END
INSSET - 2016

Ce(tte) œuvre est mise à disposition selon les termes de la Licence Creative Commons Attribution - Partage dans les Mêmes Conditions 3.0 France.