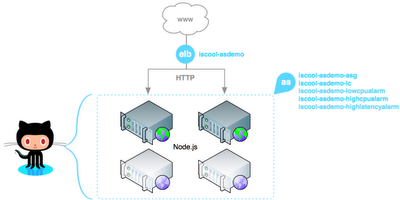
Nous allons utiliser l’AutoScaling AWS pour mettre en place un webservice de manipulation d’images qui puisse s’adapter à la charge entrante tout en minimisant les coûts de possession. Pour cela, nous allons partir d’une AMI, automatiser intégralement son lancement, puis l’injecter dans la configuration de notre groupe d’autoscaling afin de pouvoir faire varier le nombre de machines derrière un Elastic Load Balancer.
Pour information, nous allons utiliser une AMI Amazon sur laquelle nous allons installer NodeJS, ImageMagick et node-imageable-server, pour fournir un webservice basique (qui tournera en root sur le port 80). Il est également nécessaire d’installer aws-cli.
Afin d’aller à l’essentiel (cette partie du job peut tout à fait être effectuée par un outil d’orchestration comme Puppet), nous utiliserons les user-data de l’instance pour injecter un script shell exécuté en fin de boot. Celui-ci est en charge :
L’ensemble du script de lancement à passer en user-data est fourni en pièce-jointe de cette page user-data-imageable. A noter qu’il est primordial de minimiser le temps de boot d’une instance afin que notre groupe d’autoscaling soit suffisamment réactif en cas de pic de charge. Nous allons maintenant pouvoir déclarer les éléments d’infrastructure : ELB et AutoScaling
On déclare un ELB nommé upicardie-asdemo sur la zone us-east-1d, qui écoute sur le port 80 et qui répartit les requêtes sur le port 80 des instances :
Attention, avec un compte amazon VPC (ce qui est maintenant le cas par défaut), on oublie la notion de zone lors de la création de l’ELB. Par contre, on se base sur les “subnets” VPC.
aws ec2 describe-subnets
{
"Subnets": [
{
"VpcId": "vpc-ab8e3dce",
"CidrBlock": "172.31.16.0/20",
"MapPublicIpOnLaunch": true,
"DefaultForAz": true,
"State": "available",
"AvailabilityZone": "us-east-1a",
"SubnetId": "subnet-19c2126e",
"AvailableIpAddressCount": 4089
},
{
"VpcId": "vpc-ab8e3dce",
"CidrBlock": "172.31.32.0/20",
"MapPublicIpOnLaunch": true,
"DefaultForAz": true,
"State": "available",
"AvailabilityZone": "us-east-1d",
"SubnetId": "subnet-3f0e1c17",
"AvailableIpAddressCount": 4087
},
{
"VpcId": "vpc-ab8e3dce",
"CidrBlock": "172.31.0.0/20",
"MapPublicIpOnLaunch": true,
"DefaultForAz": true,
"State": "available",
"AvailabilityZone": "us-east-1b",
"SubnetId": "subnet-d9bd4f80",
"AvailableIpAddressCount": 4091
}
]
}On peut reporter les subnets qui nous interessent dans la création du load-balancer.
aws elb create-load-balancer \
--subnets subnet-d9bd4f80 subnet-3f0e1c17 subnet-19c2126e \
--load-balancer-name upicardie-asdemo \
--listeners "LoadBalancerPort=80,InstancePort=80,Protocol=http"
{
"DNSName": "upicardie-asdemo-992010360.us-east-1.elb.amazonaws.com"
}On configure ses tests de viabilité d’une instance :
aws elb configure-health-check \
--load-balancer-name upicardie-asdemo \
--health-check Target="HTTP:80/",Interval=10,Timeout=5,UnhealthyThreshold=2,HealthyThreshold=2
{
"HealthCheck": {
"HealthyThreshold": 2,
"Interval": 10,
"Target": "HTTP:80/",
"Timeout": 5,
"UnhealthyThreshold": 2
}
}Ces tests sont vitaux afin de s’assurer que l’instance cible ne rentre dans l’ELB que quand elle est pleinement opérationnelle (à l’issue de son boot via user-data)
Avant de déclarer le groupe d’autoscaling à proprement parler, nous allons définir tout ce qui est relatif à une instance du groupe, à savoir :
aws autoscaling create-launch-configuration \
--launch-configuration-name upicardie-asdemo-lc \
--image-id ami-e7de9b82 \
--instance-type t2.micro \
--user-data file://user-data-imageable \
--key-name MyKeyPair
{}aws autoscaling describe-launch-configurations
{
"LaunchConfigurations": [
{
"UserData": "...XXXXX..."
"EbsOptimized": false,
"LaunchConfigurationARN": "arn:aws:autoscaling:us-east-1:447005562149:launchConfiguration:0141a8f5-1cad-4dfc-a62f-7f012e02f067:launchConfigurationName/upicardie-asdemo-lc",
"InstanceMonitoring": {
"Enabled": true
},
"ImageId": "ami-e7de9b82",
"CreatedTime": "2014-09-15T18:23:37.312Z",
"BlockDeviceMappings": [],
"KeyName": "kp_test",
"SecurityGroups": [
...
],
"LaunchConfigurationName": "upicardie-asdemo-lc",
"KernelId": null,
"RamdiskId": null,
"InstanceType": "t2.micro"
}
]
}
Maintenant que nous avons défini la configuration de lancement, nous pouvons déclarer le groupe d’autoscaling avec les paramètres suivants :
aws autoscaling create-auto-scaling-group \
--auto-scaling-group-name upicardie-asdemo-asg \
--launch-configuration-name upicardie-asdemo-lc \
--availability-zones us-east-1d \
--min-size 0 --max-size 0 \
--load-balancer-names upicardie-asdemo \
--health-check-type EC2 \
--health-check-grace-period 300aws autoscaling describe-auto-scaling-groups
{
"AutoScalingGroups": [
{
"AutoScalingGroupARN": "arn:aws:autoscaling:us-east-1:447005562149:autoScalingGroup:467e886b-ede8-40eb-9338-a6bd9f53f3af:autoScalingGroupName/upicardie-asdemo-asg",
"HealthCheckGracePeriod": 300,
"SuspendedProcesses": [],
"DesiredCapacity": 0,
"Tags": [],
"EnabledMetrics": [],
"LoadBalancerNames": [
"upicardie-asdemo"
],
"AutoScalingGroupName": "upicardie-asdemo-asg",
"DefaultCooldown": 300,
"MinSize": 0,
"Instances": [],
"MaxSize": 0,
"VPCZoneIdentifier": null,
"TerminationPolicies": [
"Default"
],
"LaunchConfigurationName": "upicardie-asdemo-lc",
"CreatedTime": "2014-09-15T18:24:56.744Z",
"AvailabilityZones": [
"us-east-1d"
],
"HealthCheckType": "EC2"
}
]
}Il est ensuite nécessaire de définir la politiques de mises à
l’échelle de l’architecture, à la hausse comme à la baisse. Chaque
élément AWS (ELB, volume, instance…) dispose de métriques CloudWatch sur
lesquelles nous allons nous appuyer pour lancer ou éteindre des
machines. Les instances d’un groupe d’autoscaling disposent notamment
d’une surveillance CloudWatch détaillée (pas de 1 minute à la place des
5 minutes par défaut). Commençons par définir notre politique d’ajout de
machines (upicardie-asdemo-scale-up) : Nous ajoutons 50% de machines en
plus. Le paramètre --cooldown permet de définir une durée
(en seconde) pendant laquelle la politique de mise à l’échelle ne sera
plus appelée. C’est utile pour laisser les instances se lancer et pour
voir les premiers bénéfices de l’ajout d’instances.
aws autoscaling put-scaling-policy \
--policy-name upicardie-asdemo-scale-up \
--auto-scaling-group-name upicardie-asdemo-asg \
--scaling-adjustment 50 \
--adjustment-type PercentChangeInCapacity \
--cooldown 300
{
"PolicyARN": "arn:aws:autoscaling:us-east-1:447005562149:scalingPolicy:c7d0ed93-f391-43e4-91a3-e9e977dbb6f3:autoScalingGroupName/upicardie-asdemo-asg:policyName/upicardie-asdemo-scale-up"
}Même chose pour le retrait de machine : on enlève les machines une à une du groupe d’autoscaling. L’idée est ici de croitre beaucoup plus vite qu’on ne décroit pour pouvoir encaisser facilement des pics de charge successifs.
aws autoscaling put-scaling-policy \
--policy-name upicardie-asdemo-scale-down \
--auto-scaling-group-name upicardie-asdemo-asg \
--scaling-adjustment -1 \
--adjustment-type ChangeInCapacity \
--cooldown 300
{
"PolicyARN": "arn:aws:autoscaling:us-east-1:447005562149:scalingPolicy:84ece9a9-759f-4230-996d-83c132935b1e:autoScalingGroupName/upicardie-asdemo-asg:policyName/upicardie-asdemo-scale-down"
}L’invocation des commandes ci-dessus renvoie à chaque fois une référence que nous allons pouvoir injecter dans nos déclencheurs… A commencer par la mise à l’échelle à la hausse lorsque :
--statistic Average --metric-name CPUUtilization)--namespace "AWS/EC2" --dimensions "Name=AutoScalingGroupName,Value=upicardie-asdemo-asg")--comparison-operator GreaterThanThreshold)--threshold 70)aws cloudwatch put-metric-alarm \
--alarm-name upicardie-asdemo-highcpualarm \
--comparison-operator GreaterThanThreshold \
--statistic Average \
--metric-name CPUUtilization \
--namespace "AWS/EC2" \
--dimensions "Name=AutoScalingGroupName,Value=upicardie-asdemo-asg" \
--period 60 \
--threshold 70 \
--evaluation-periods 2 \
--alarm-actions arn:aws:autoscaling:us-east-1:447005562149:scalingPolicy:c7d0ed93-f391-43e4-91a3-e9e977dbb6f3:autoScalingGroupName/upicardie-asdemo-asg:policyName/upicardie-asdemo-scale-up
{}Pareil avec la mise à l’échelle à la baisse lorsque :
--statistic Average --metric-name CPUUtilization)--namespace "AWS/EC2" --dimensions "Name=AutoScalingGroupName,Value=upicardie-asdemo-asg")--comparison-operator LessThanThreshold)--threshold 36)--period 60 --evaluation-periods 2)aws cloudwatch put-metric-alarm \
--alarm-name upicardie-asdemo-lowcpualarm \
--comparison-operator LessThanThreshold \
--statistic Average \
--metric-name CPUUtilization \
--namespace "AWS/EC2" \
--dimensions "Name=AutoScalingGroupName,Value=upicardie-asdemo-asg" \
--period 60 \
--threshold 36 \
--evaluation-periods 2 \
--alarm-actions arn:aws:autoscaling:us-east-1:447005562149:scalingPolicy:84ece9a9-759f-4230-996d-83c132935b1e:autoScalingGroupName/upicardie-asdemo-asg:policyName/upicardie-asdemo-scale-down
{}Nous allons ensuite prendre soin de la QoS de notre service en définissant une mise à l’échelle à la hausse lorsque :
--statistic Average --metric-name Latency)--namespace "AWS/ELB" --dimensions "Name=LoadBalancerName,Value=upicardie-asdemo")--comparison-operator LessThanThreshold)--threshold 3)--period 60 --evaluation-periods 1)aws cloudwatch put-metric-alarm \
--alarm-name upicardie-asdemo-highlatencyalarm \
--comparison-operator GreaterThanThreshold \
--statistic Average \
--metric-name Latency \
--namespace "AWS/ELB" \
--dimensions "Name=LoadBalancerName,Value=upicardie-asdemo" \
--period 60 \
--threshold 3 \
--evaluation-periods 1 \
--alarm-actions arn:aws:autoscaling:us-east-1:447005562149:scalingPolicy:c7d0ed93-f391-43e4-91a3-e9e977dbb6f3:autoScalingGroupName/upicardie-asdemo-asg:policyName/upicardie-asdemo-scale-up
{}Notre autoscaling est dorénavant fonctionnel. Pour lancer le service, il suffit de passer le min/max du nombre d’instances du groupe d’autoscaling de 0/0 à 2/12 par exemple :
aws autoscaling update-auto-scaling-group \
--auto-scaling-group-name upicardie-asdemo-asg \
--min-size 2 \
--max-size 12
{}Dans certains cas, il est possible de prévoir la charge sur la plate-forme et de programmer, à une certaine heure et une certaine récurrence la mise à l’échelle de l’autoscaling en jouant sur le min/max par exemple. Les deux régles suivantes vont définir un passage à 3 instances minimum à 22h15 UTC chaque jour (syntaxe cron) :
aws aws autoscaling put-scheduled-update-group-action \
--auto-scaling-group-name upicardie-asdemo-asg \
--scheduled-action-name upicardie-asdemo-preemptive-upscale \
--min-size 4 \
--max-size 12 \
--recurrence "15 22 * * *"
{}suivi d’un retour à 2 instances minimum à 4h00 UTC chaque jour :
aws aws autoscaling put-scheduled-update-group-action \
--auto-scaling-group-name upicardie-asdemo-asg \
--scheduled-action-name upicardie-asdemo-preemptive-downscale \
--min-size 2 \
--max-size 12 \
--recurrence "0 4 * * *"
{}Les commandes d’autoscaling prévoient la mise à jour du groupe d’autoscaling, mais pas de la configuration de lancement de ce même groupe. Qu’importe, nous pouvons contourner cette limitation en passant une configuration de lancement temporaire. Si nous voulons par exemple retirer les security groupes de notre groupe de lancement.
aws autoscaling create-launch-configuration \
--launch-configuration-name upicardie-asdemo-lc2 \
--image-id ami-e7de9b82 \
--instance-type t2.micro \
--user-data file://user-data-imageable \
--key MyKeyPair
aws autoscaling update-auto-scaling-group \
--auto-scaling-group-name upicardie-asdemo-asg \
--launch-configuration-name upicardie-asdemo-lc-2
aws autoscaling delete-launch-configuration \
--launch-configuration-name upicardie-asdemo-lcNote : cette double déclaration de configurations de lancement peut être évitée si on horodate le nom de la configuration plutôt que de le garder fixe.
Siege permet de simuler de la charge sur service web, en maintenant ouvert des dizaines voir centaines de connexions pendant une temps défini.
sudo apt-get install siegeIl suffit de donner à siege le nombre de connexions concurrentes
(-c), et le temps du test (-t).
siege -c25 -t10M upicardie-asdemo-992010360.us-east-1.elb.amazonaws.comUn équivalent à Apache Benchmark.
pip install boomPuis
boom -c 5 -n 100 "http://upicardie-asdemo-992010360.us-east-1.elb.amazonaws.com/resize/magic?url=http://www.google.com/intl/en_ALL/images/logo.gif&size=400x300"Une chose à noter est que le monitoring basique de CloudWatch est rafraichi toutes les 5 minutes. Nos politiques d’auto-scaling doivent se réaliser pendant 3 minutes consécutives. Donc, pour que siege puisse déclencher l’auto-scaling, il faut le laisser tourner 6 à 10 minutes. Enfin, il faut rafraichir l’onglet CloudWatch dans la console AWS afin de vérifier que des serveurs se lancent.
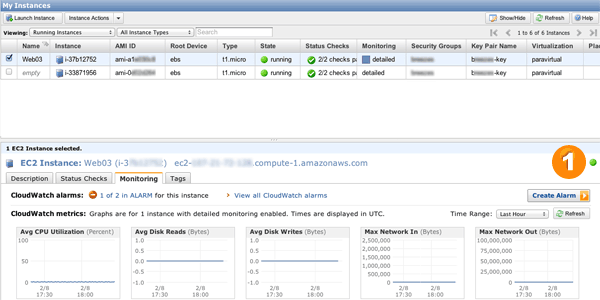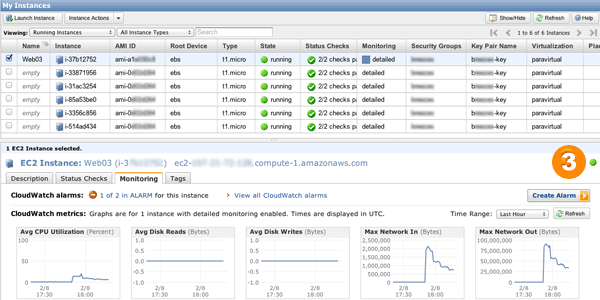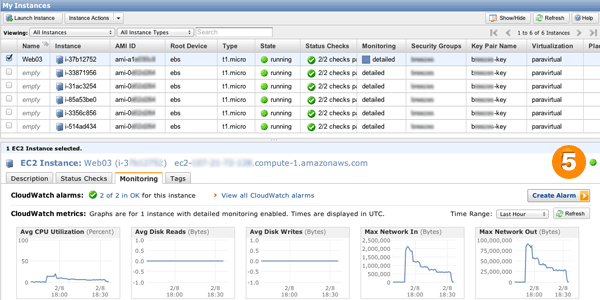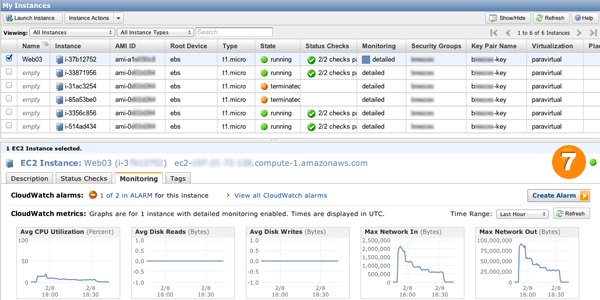
Post-scriptum : Pour quasiment la même chose en 1 clic, passez voir Elastic Beanstalk :)
Cette œuvre est mise à disposition selon les termes de la Licence Creative Commons Attribution 3.0 France.
